Quick take
Personal devices, whether they are smartphones or wearables, are becoming increasingly intelligent, thanks to advances in artificial intelligence (AI). The Device Software Research team at Nokia Bell Labs is at the forefront of developing efficient, collaborative, and adaptive AI for personal devices. In this article, we will examine our work and explore its potential to revolutionize the way we interact with our devices, making them more helpful, personalized, and responsive.
Introduction
Imagine wearing an earbud throughout the day, helping you stay productive, efficient, healthy, and happy. Your AI-assisted earbud knows you, learns your preferences, and seamlessly adapts to you and your lifestyle without any manual effort. Thanks to fundamental research advancements made by the Nokia Bell Labs Device Research Team in Cambridge, we are on the brink of integrating these highly intelligent personal devices into our daily lives.
Creating such an AI-assisted earbud necessitates solving a series of fundamental problems to equip the device with three unique and essential functionalities:
- Providing unique, personalized recommendations based on your situation or current activity. For instance, this could be switching audio to noise canceling to focus while you’re working or reminding you to take a break if you’ve been stationary at your laptop for too long. By analyzing your activity patterns through data-efficient AI, the AI-assisted earbud is able to provide these customized suggestions. Using self-supervised learning techniques, the earbud can make sense of unlabeled data coming from several of your devices, such as your fitness tracker, phone, or computer, to understand if you are sitting stationary or if there is some kind of background noise and you are also logged into your computer. By being exposed to diverse unlabeled data the earbud gets better at extracting meaningful patterns, letting it provide personalized recommendations for optimizing your health and productivity without any exhaustive manual data labeling.
- Teaching itself about you without sharing your data – anywhere. Your AI-powered earbud can learn more about you by connecting seamlessly with data from other personal devices you may be carrying – such as a smart ring or phone. Using collaborative AI, the AI-assisted earbud safeguards your privacy through collaborative learning. Rather than hoarding all your data in a centralized server, it uses federated learning to train on device and benefit from other personal devices’ information. Your phone’s personal assistant may have a better understanding and recognition of your voice, for example, so training with that data can improve its own responses to you. This allows the AI earbud to learn from a wealth of diverse data points while keeping your personal data localized on your device. It gets smarter without compromising your privacy.
- Improving through diverse data. The earbud uses data-centric AI models to handle varied data types. This means that the earbud learns from different representations of the same information. For example, its models can use data from the microphones of all kinds of devices, whether that’s a smart speaker, smartphone, a smartwatch or even from other users, and then adjust its data to include all potential variabilities to improve speech recognition. This allows the earbud to build a much better picture of you and your needs. Just as humans learn from experiencing diverse situations, the AI-powered earbud thrives on data diversity. So, whether you're walking, running, resting, or working, it continually refines its intelligence.
Making the most of available data
Training AI models typically requires massive, labeled datasets, which can be laborious and expensive to collect. The Device Software Research team has pioneered techniques to make AI more data-efficient by utilizing unlabeled data.
Our Collaborative Self-Supervised Learning (ColloSSL) solution performs human activity recognition using unlabeled data from multiple wearable devices. Activity recognition is a fundamental task in personal devices that, for example, can detect falls and notify your family or emergency services. ColloSSL advances the current state of the art in self-supervised learning by proposing a new modeling method that considers both spatial (device body position) and temporal (data synchronization) perspectives.
A key insight that underpins the design of ColloSSL is that heart rate or step count signals simultaneously captured by multiple devices can be viewed as natural transformations of each other, providing valuable information without any additional annotation. To use an analogy, imagine a study group of students helping each other without the need for a teacher. By using this approach through a multi-view contrastive objective, it outperformed competitive models, achieving 7.9% higher accuracy by exploiting solely unlabeled data.
Another thorny problem in AI is learning from structurally different data sources (modalities). Multimodal learning allows AI systems to understand diverse data types like audio, video, and sensor data. But labeled multimodal datasets are scarce, hampering progress in this area. To overcome this bottleneck, we introduced Cross-modal Self-Supervised Learning (CroSSL) for multimodal time-series data. It uses a novel latent masking technique during pre-training that hides part of the latent representation of a modality. The model must then reconstruct the masked representations using a contrastive objective.
By hiding its internal inputs, the model learned to fill the gaps, which translated to improved performance. CroSSL was evaluated on multimodal medical-grade (EMG, EEG) and consumer biosignals (ECG), and indeed outperformed existing self-supervised methods by 7.2% on average. By pre-training with CroSSL before fine-tuning on downstream tasks, models can learn robust joint representations from unlabeled multisensory data. This is a promising step towards data-efficient multimodal AI – particularly in the sparse-label regime that is common in the personal device space. We discuss CroSSL in depth in our upcoming paper at the International Conference on Web Search and Data Mining (WSDM 2024).
But what if you pick up a new sport or habit? How can your device pick it up? Continual learning allows AI systems to learn sequentially from new data over time, like humans. But when learning new information, AI models tend to catastrophically forget knowledge learned previously. To address this, we propose Self-Supervised Continual Learning (called Kaizen, from the east-Asian concept of continual improvement). Kaizen leverages both labeled and unlabeled data. It uses a novel objective that balances preserving old knowledge and learning new information during training.
We evaluated Kaizen on popular image-recognition benchmarks on which it achieved up to 16.5% higher accuracy compared to other continual learning techniques. Kaizen works like revising class notes – both reviewing previous material and writing new content help retain information and interconnect concepts. The unlabeled data acts as the raw material for the AI to revise its knowledge representations. Kaizen will be presented at the Winter Conference on Applications of Computer Vision (WACV 2024).
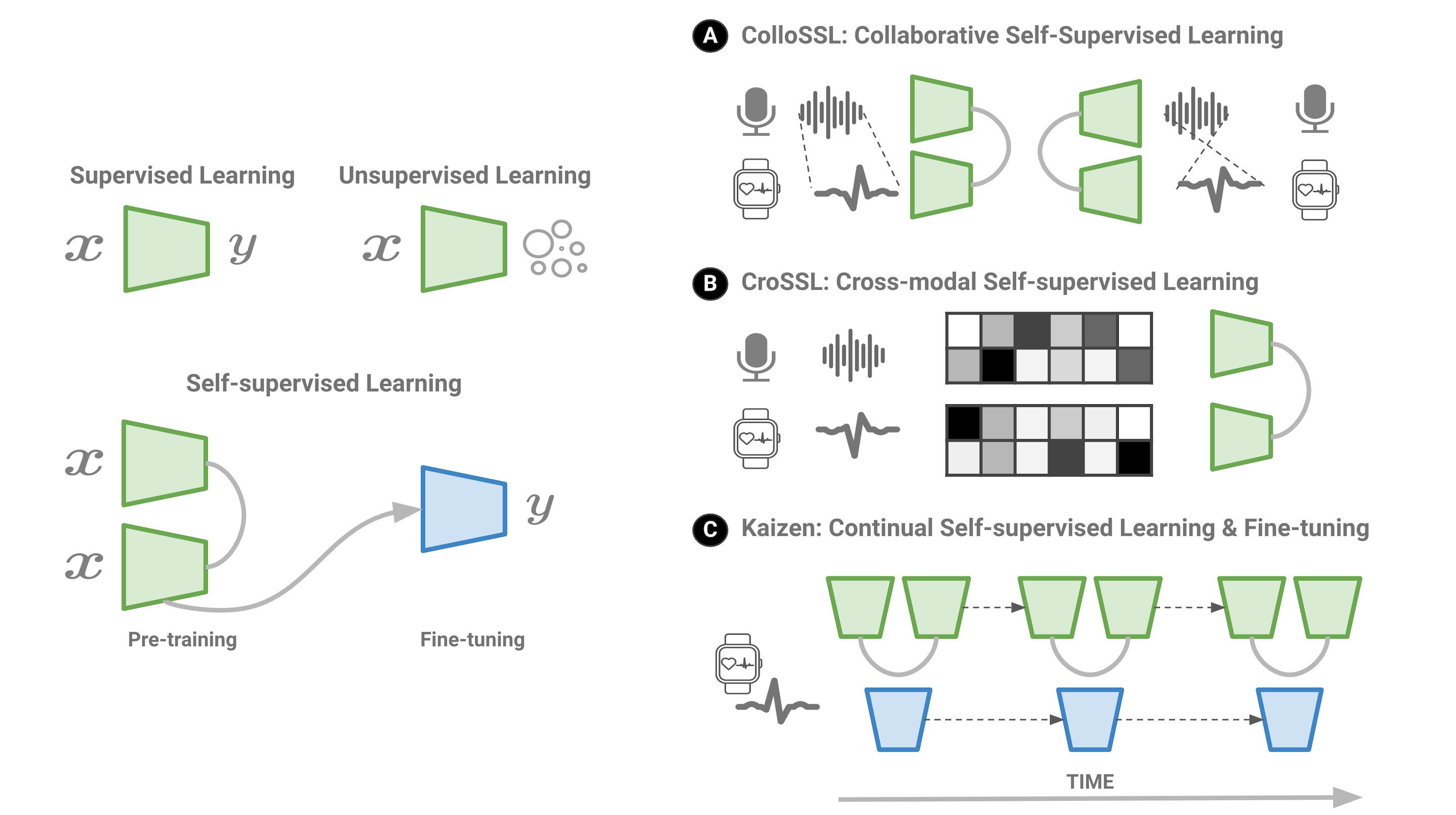
Figure 1. An overview of data-efficient AI through self-supervised learning. Compared to other approaches like supervised or unsupervised learning, here we first pre-train based on unlabeled data and then fine-tune with domain-specific samples. (A) ColloSSL proposed a new contrastive objective where data from synchronized timesteps and various body positions are used as proxy targets for training an on-device model. (B) CroSSL introduced two latent masks that learn cross-modal patterns from different sources within a contrastive objective. (C) Kaizen proposed knowledge distillation across both the pre-training and fine-tuning steps in order to improve continual learning.
Learning together while keeping data private
Federated learning is like organizing a potluck dinner. Each person brings a homemade dish to share without giving up their secret recipe. Everyone gets to enjoy a variety of cuisines while the recipes remain private. Similarly, federated learning allows multiple devices to collaboratively train an AI model without sharing raw data. Each device contributes model updates based on its local data. The updates are aggregated to improve the global model.
This way, models benefit from diverse and distributed data points while user data remains private on devices. But there are still some unsolved problems to overcome in order to scale to real-world settings.
Heterogeneous user data makes federated learning challenging and existing approaches rely on labeled data, and thus struggle to scale. To enable privacy-preserving federated learning on diverse unlabeled data, we propose Unsupervised Federated Learning via Globally Consistent Clustering (Orchestra) which uses hierarchical clustering to partition unlabeled data from different devices into groups. This is like organizing an orchestra by instrument sections – clustering violinists together, grouping clarinets, etc.
We evaluated Orchestra using data from hundreds of devices and showed an accuracy improvement of 7% using 94% less labeled data compared to models trained from scratch. Orchestra demonstrates that clustering user data helps scale federated learning to large heterogeneous setups. Orchestra was presented in the International Conference of Machine Learning (ICML).
Resource constraints are usually the bottleneck in on-device AI. Many edge devices like smartwatches have limited computing power. This constrains their ability to participate in collaborative learning. To enable federated learning on such ultra-constrained devices, we developed Federated Learning for Constrained Edge Devices (Centaur), which combines data selection and partitioned training. Centaur is like a team of horses pulling a cart – combining the strengths of both powerful and small horses. It selects small representative data samples on the device to reduce communication costs, and this sample is used to pretrain a model locally.
This model is then further trained on the powerful user device. By partitioning training across devices, Centaur reduces energy consumption on edge devices by 58% while improving accuracy. Centaur demonstrates that federated learning can be extended to low-power IoT devices through careful data sampling and split training. Like horses paired by strength, it allows devices to contribute to collaborative learning according to their capabilities.
Training models collaboratively from multiple user devices also leads to statistical differences in data distributions. This heterogeneity impedes federated learning. To address this, we introduced Federated Learning Across Multi-device Environments (FLAME), which utilizes time alignment of data and resource-awareness across a user's devices. FLAME operates similarly to a well-coordinated soccer team on the field, meticulously selecting devices and synchronizing data sampling to minimize heterogeneity. This ensures that the optimal devices are chosen, akin to selecting players who are in the right condition and have the appropriate energy levels for the game.
FLAME achieved 25% higher accuracy and 2.8x better efficiency compared to competitive approaches and demonstrated that aligning data distributions and strategic selection of devices improves collaborative learning.
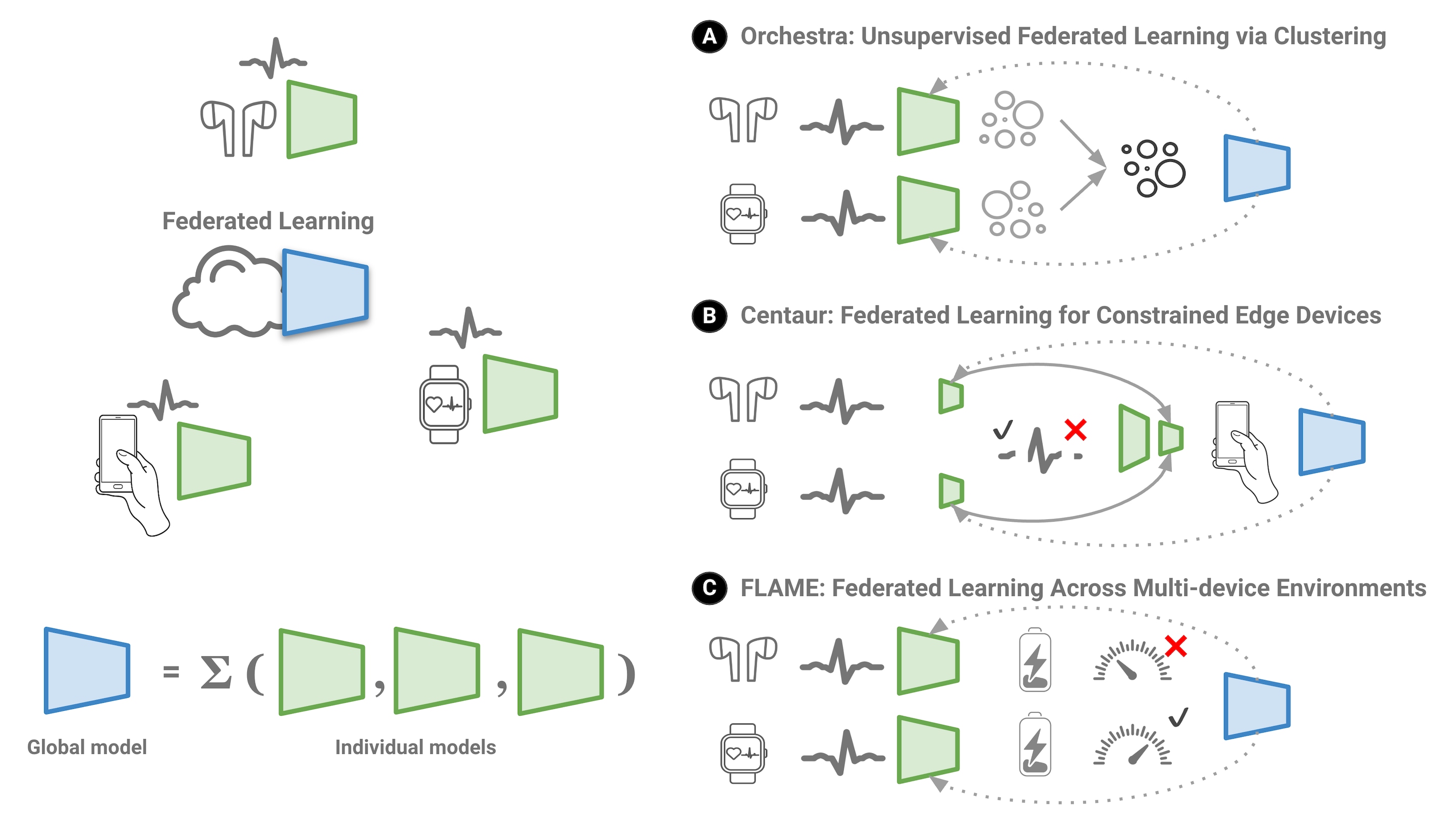
Figure 2. Federated learning trains individual models on user devices and updates the cloud model without sharing any private data. The cloud aggregates the individual models and sends them back to the users in order to continue the learning process. (A) Orchestra proposed an elegant clustering algorithm to improve unsupervised federated learning. (B) Centaur put forward a data selection and model split mechanism to enable training in constrained devices. (C) FLAME integrated constraints for efficient device selection within the federated learning paradigm.
There is no model without data
While the above approaches focused on models, data-centric AI brings the data to the spotlight and aims to handle diverse data distributions. We are advancing techniques to make models robust to varied data types and domains through generative AI.
For instance, to make speech systems more robust on personal devices, we developed Mic2Mic, which uses generative adversarial networks, a popular AI model that generates new data, to convert speech data between microphones. Mic2Mic is like a vocal coach teaching singers to adapt their voices. It learns to transform audio signals between microphones, recovering up to 89% accuracy lost due to microphone differences.
This allows models to generalize better, so they work reliably for individuals using different devices. Mic2Mic demonstrates data augmentation through generative models to address variability in speech systems. Just as a coach helps singers master diverse acoustics, Mic2Mic teaches AI models to handle the intricacies of multi-microphone audio data. It paves the path for robust speech recognition that works consistently for all users.
Beyond speech, Large Language Models (LLMs) like ChatGPT are masters in manipulating language but struggle to represent time-series data like sensor readings. Their textual foundations lead to an incorrect understanding of numeric data. In a recent case study, we showed that directly feeding sensor data like heart rate or steps to LLMs results in suboptimal representations, because such models fail to capture temporal relationships. This is like trying to tell a story by just listing events in a random order, without establishing connections between them. LLMs tokenize each sensor reading independently, losing vital temporal context.
To overcome this, we advocate for solutions like prompt tuning and multimodal adapters. These will help adapt language models to effectively ingest temporal data, fusing numerical representations with text. Just as a story weaves events together, such techniques will empower LLMs to seamlessly integrate time-series data.
In addition to generative AI, our team is actively working on a broad range of data-centric AI topics, including new methods to enhance privacy through split inference as well as quantifying the impact of AI biases in personal devices.
AI will redefine our interactions with personal devices
Our research pushes the boundaries of data efficiency, collaboration, and robustness in AI. We have developed techniques that require less data annotation, enable decentralized learning, and handle diverse distributions. This lays the groundwork for more personalized, adaptable, and trustworthy device intelligence. As devices become intelligent assistants, our innovations help make them seamless companions that enable new experiences.
The future promises AI-enabled devices that learn fluidly like humans – collaboratively, incrementally, and from diverse experiences. Datasets and labels will fade to the background as on-device models gain the ability to self-improve through collective knowledge and unlabeled real-world sensory observations. We stand at the cusp of a new era where AI-enabled devices and humans learn and grow symbiotically. Our team's contributions bring this vision closer through advancements at the frontiers of machine learning.
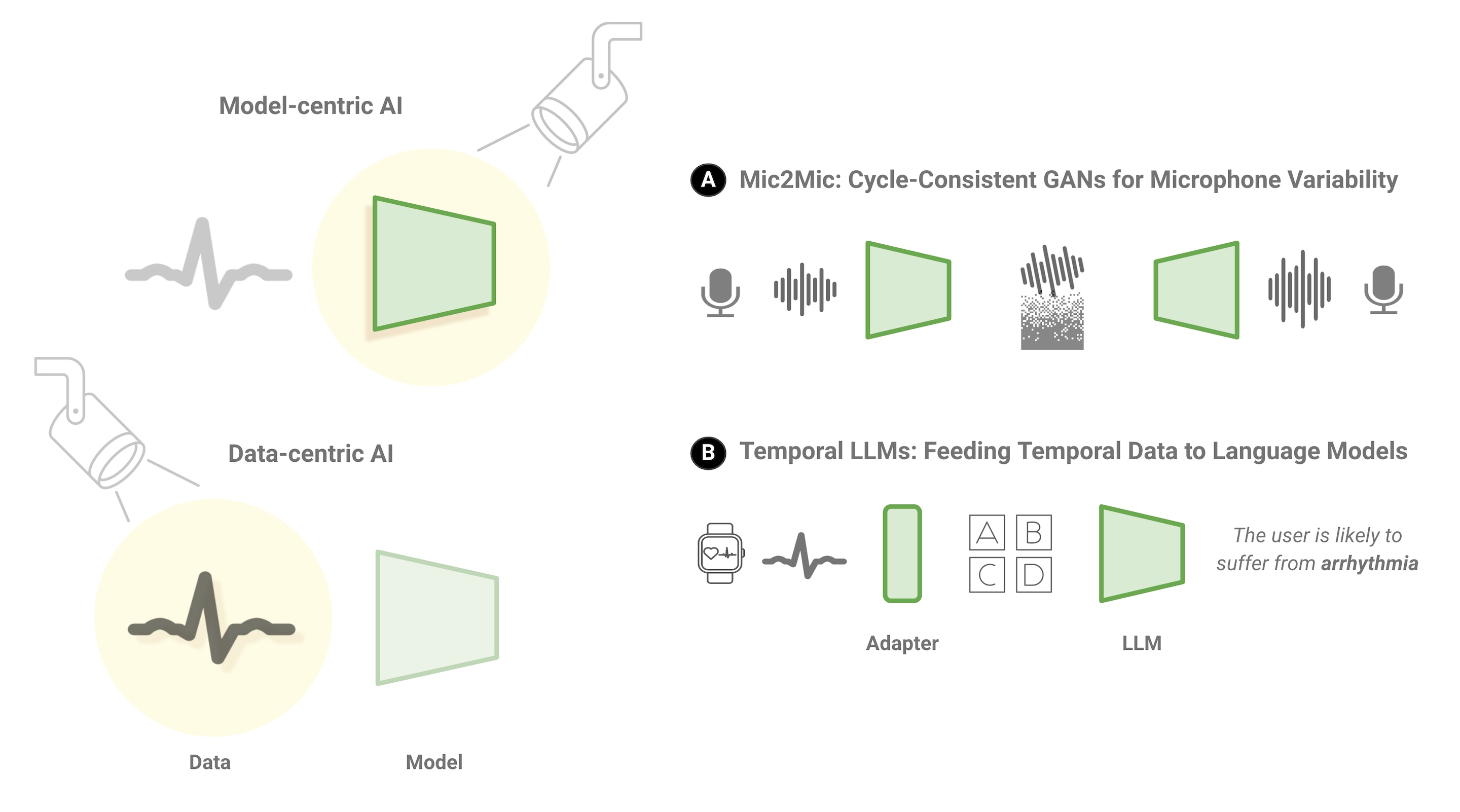
Figure 3. Data-centric AI brings data to the spotlight by focusing on its unique characteristics. (A) Mic2Mic used Generative Adversarial Networks to automatically transform audio signals between microphones enabling improved generalization. (B) Temporal LLMs pave the way for multimodal inputs to Large Language Models by adapting the input tokens to an LLM understandable representation.
Acknowledgements
This research received valuable contributions from various members of the Device Software Research team including Soumyajit Chatterjee, Mohammad Malekzadeh, Lorena Qendro, Dimitris Spathis, Ian Tang, and Fahim Kawsar. We extend our gratitude to Akhil Mathur, Yash Jain, Shohreh Deldari, Ekdeep Singh Lubana, Fan Mo, and Hyunsung Cho, who played an active role in the research presented here.
Author
Discover more

Video
AI-enhance wireless reliability: joint source and channel coding for robust 6G air interface

Blog

Blog

Podcast