Network equipment and applications produce massive amounts of text-based data. Unstructured data is ubiquitous, and its lack of structure makes it difficult to analyze as opposed to structured data like databases. Consequentially, applications built on top of this data first require extracting the relevant data, which is time-consuming and cumbersome from the developer. The goal of the automatic parsing project is to automate this task to accelerate the development of applications.
Background
Text-based data is ubiquitous in network and system management: system command results and events recorded by the applications in log files are both text-based data. As such data is unstructured, querying is less handy than fetching data from structured data like databases. However, this data is often important, for instance to develop dashboards allowing to monitor the health network infrastructure or to detect network attacks. In practice, such software first converts the unstructured data they need, and transforms it to structured data so that it becomes easier to manipulate. This common programming task is called parsers. Developing a parser is not so difficult, but it is a time-consuming, cumbersome and error-prone process. Moreover, a single operating system involves dozens of file formats and hundreds of command systems and developing a parser for each of them hardly scales.
At Nokia, this problem arose when one of our businesses had to design a network monitoring solution on top of a cloud mobility manager (CMM). Dozens of engineers spent significant effort using TextFSM to write parsers allowing to process the results of CMM commands.
Prior art
TextFSM allows us to write parsers by specifying processing operations on top of a finite state machine (FSM). Other tools exist to help network administrators load data in their program. DataWrangler or FlashExtract are less development-oriented but require human intervention to ingest the input text data. Tools like Spell, LogMine, Drain or DataMaran are specifically tailored to process log files and assume that each line involved in the file is independent. More sophisticated solutions like PADS aim at processing any kind of text having an underlying structure (e.g., tables) but are in practice hard to install and to use.
Besides its technical relevancy, this project raises challenging research questions and is closely related to the grammar induction research field. Given a set of input texts that conform to the same unknown template, the goal is to infer an accurate and readable template. Using the terminology of this research field, the goal is to infer a grammar from a (small) finite set of positive examples. There exist various kinds of grammar inductions problems. Gold and RPNI algorithms infer grammar from a finite set of positive and negative examples. As in our use case, there are no negative examples, the inferred automaton is not accurate enough to obtain relevant parsers. TKDE uses a genetic algorithm to infer grammar from positive examples but hardly scales for our use cases.
Due to their inherent limitations, none of these solutions applied in our case and we decided to design our own solution. The core idea consists in finding repeating “patterns”, as a repetition suggests the underlying data structure.
Exploit text positioning
The first idea is to use text positioning to detect tables and hierarchies. Intuitively, a table is a repetition of homogeneous rows, with or without a column separator. The example below shows the routing table of a machine running GNU/Linux, whose columns are Destination, Gateway, Genmask, Flags, Metric, Ref, Use and Iface. The text positioning shows that the flags of the three routes are respectively U, U, and UG.

Parsing such a text is straightforward with a utility like awk, but parsing a table becomes suddenly harder as in the example below, taken from Cloud Mobility Manager.
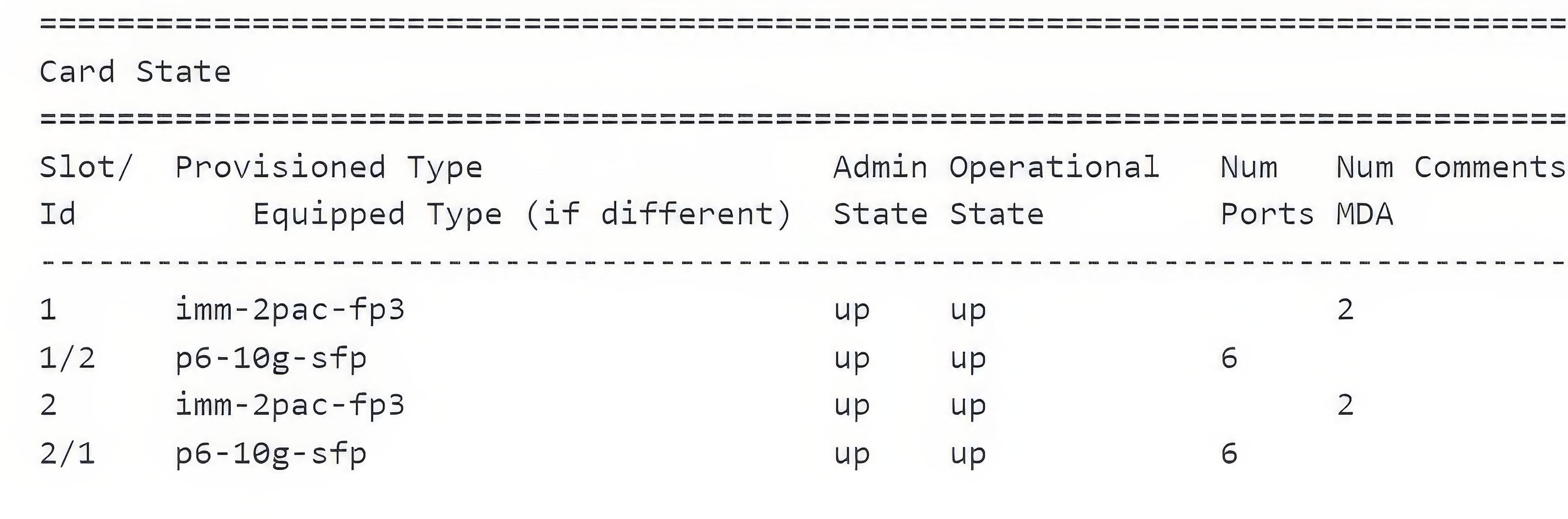
Indeed, the 5th and 6th fields (“Num Ports” and “Num MDA”) are optional, and when parsing the following rows, the 5th value may either correspond to the “Num Ports” or “Num MDA” column. The parser must hence capture the starting and ending indices to bound each column and hence map each value with the appropriate column name. Intuitively, if space characters are replaced by 0 and the other characters ones, checking whether two lines are compatible is done using a logical AND to check whether there is no contradiction with the previous line (space characters of the previous line remain space characters).
Similarly, the text indentation can be exploited to bound a hierarchical object and to characterize each of its items depending on its depth in the hierarchy.
Exploit the nature of data
In log files, each line often corresponds to a specific timestamped event. However, several events may occur at the same time and result in similar log lines. Hence, parsing a log file first involves determining all the different kinds of line it involves, then reading the file line by line and calling the appropriate parsing rule.
The log clustering problem consists in partitioning the lines involved in a log so that each cluster induces a dedicated parsing rule. LogMine and Drain are fast log clustering tools. These tools take as parameters a collection of patterns, typically representing common data types (e.g., numerical values, times, dates, URLs, file paths, network addresses, etc.). Then, for each pattern and for each line, each pattern occurrence is replaced by a dedicated wildcard. Finally, the resulting log lines are grouped by the Nearest Neighbor method using a greedy distance. By design, the result of this approach depends on the order in which the input patterns are passed to the tool. In addition to affecting the result, this also leads to an arbitrary pattern-based decomposition. Finally, if some lines of the same type have optional fields, these tools will not necessarily group them in the same cluster.
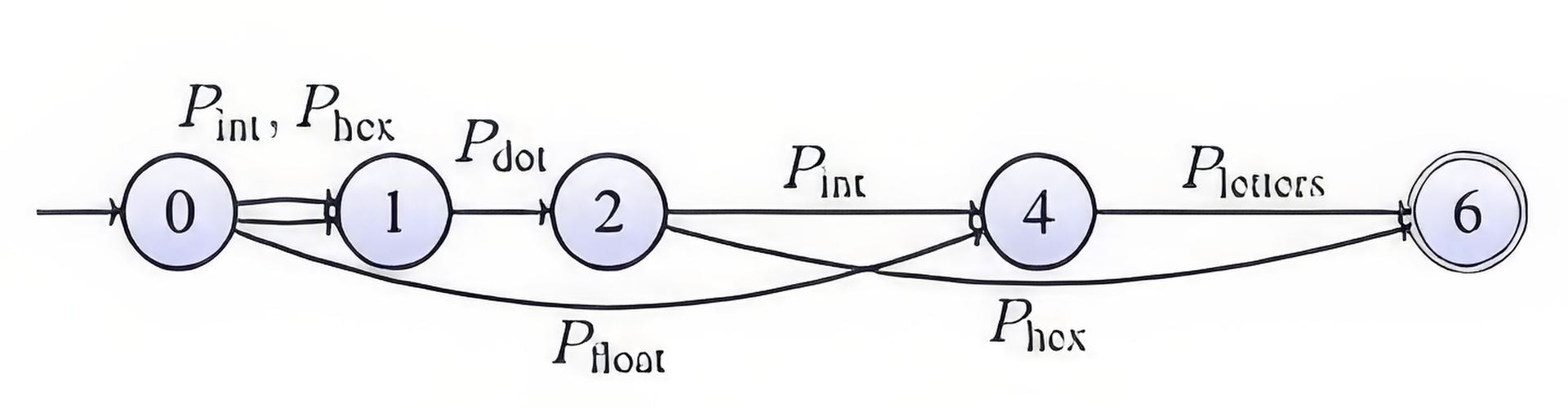
To address this problem, our tool represents each input log line using an automaton-like data structure, called a pattern automaton, that represents the input log pattern scale. Each state corresponds to an index of the input string and each transition to a pattern that recognizes the substring bounded by its source and node indices. Therefore, each path from the starting index to the ending index corresponds to a possible pattern-based decomposition of the input string. This can be easily built using a variation of the grep tool. The example below shows how “4.57AB” is transformed if the input patterns recognize integers, floating numbers, hexadecimal values, dots, and letters.
The next question is how to compare two pattern automata to determine whether they must fall in the same cluster. Comparing two strings (which eventually involves an optional substring) can be done using edit distances. This task is commonly computed in bioinformatics to compare RNA sequences using the Needleman Wunsch algorithm. This algorithm is often implemented using dynamic programing, but another more intuitive way to compute it consists in building the edit graph induced by the two compared string s1 and s2 and searching the shortest path from the state (0, 0) to (|s1|-1, |s2|-1). The example below illustrates the comparison of “47XY” against “4.57AB” using the Levenshtein distance. If every arc is weighted by 1 except for the diagonal arcs corresponding to matching characters, the cost of a shortest path in red is the Levenshtein distance between these two strings (here 0+1+1+0+1+1=4).
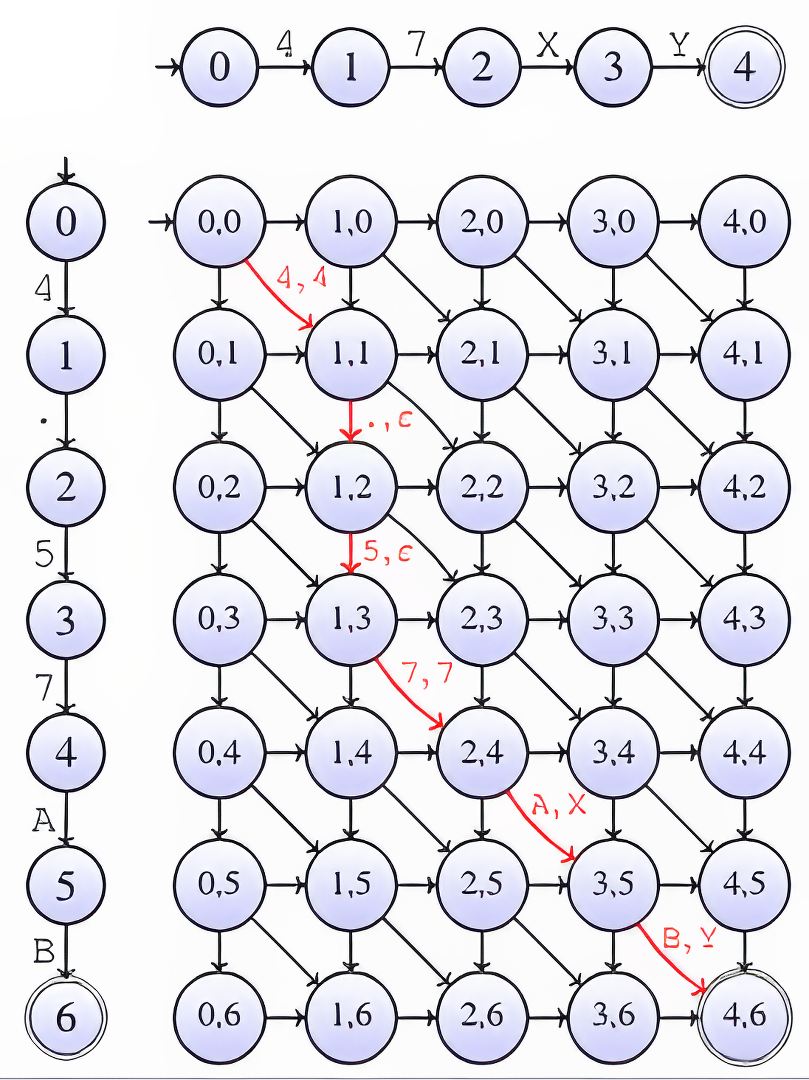
Moreover, the shortest path reveals a minimal set of character-based edit-operation allowing to transform “4.57AB” to “47XY” (that is, keep “4”, delete “.” add “5”, keep “7”, change “A” to “X” and “B” to “Y”).
The edit graph naturally generalizes for pattern automata. In our running example it becomes:
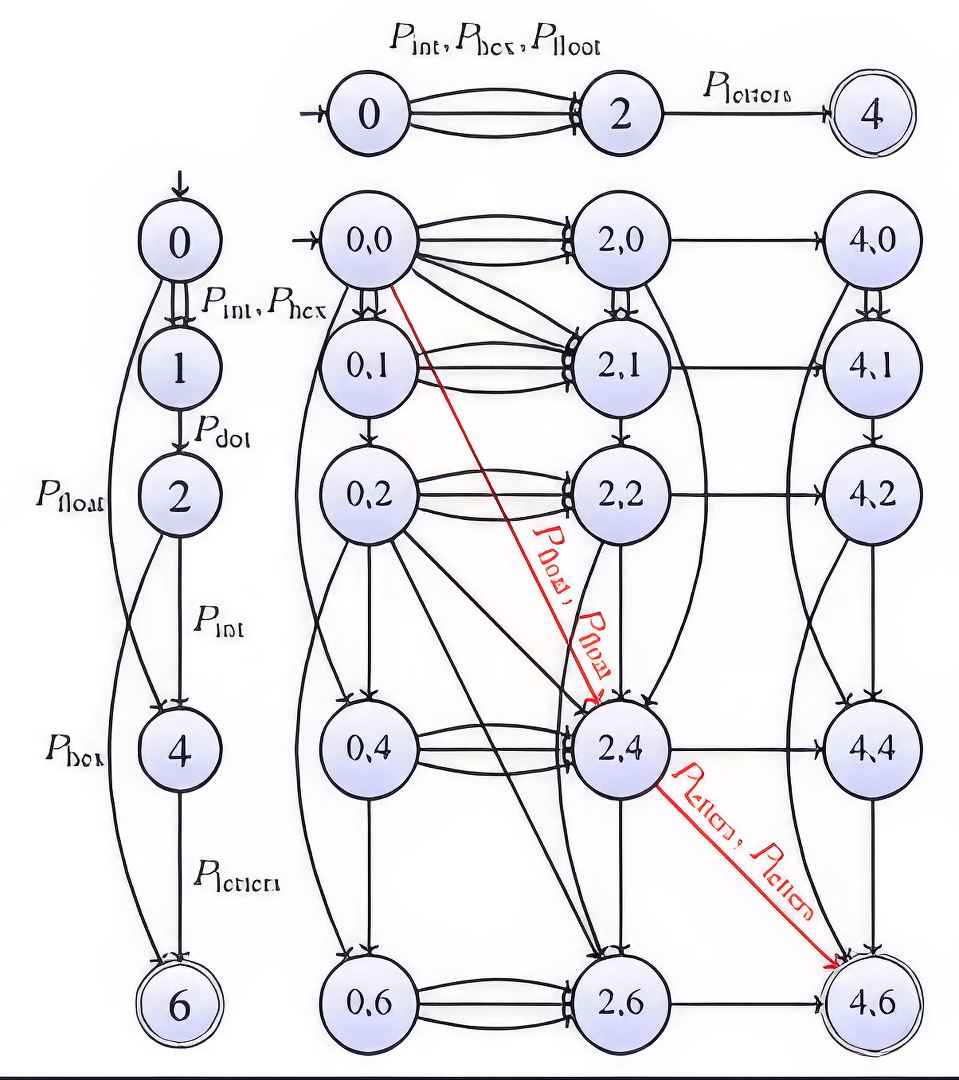
Vertical, horizontal, and diagonal edges become pattern-edit operations (here, the two input strings are made of a float followed by letters). To compare two paths, arcs are weighted using a density function that depends on the pattern: the stricter the pattern, the lower the density. Hence, the lowest the cost of the shortest path, the more accurate the decomposition. This distance, called pattern distance, can be used in any clustering algorithm, e.g., the nearest neighbor clustering. When processing a log, the clusters are therefore pattern-based.
Putting it all together
The text positioning allows us to segment the text into structures (tables) while the pattern clustering allows us to characterize types and distinguish headers and data. There are additional ingredients to accurately extract the data, for instance if a data item or a header is scattered over multiple lines of text. By wisely combining all these ingredients, we can design an algorithm that automatically extracts the nested data and produces semi structured data from the original data.
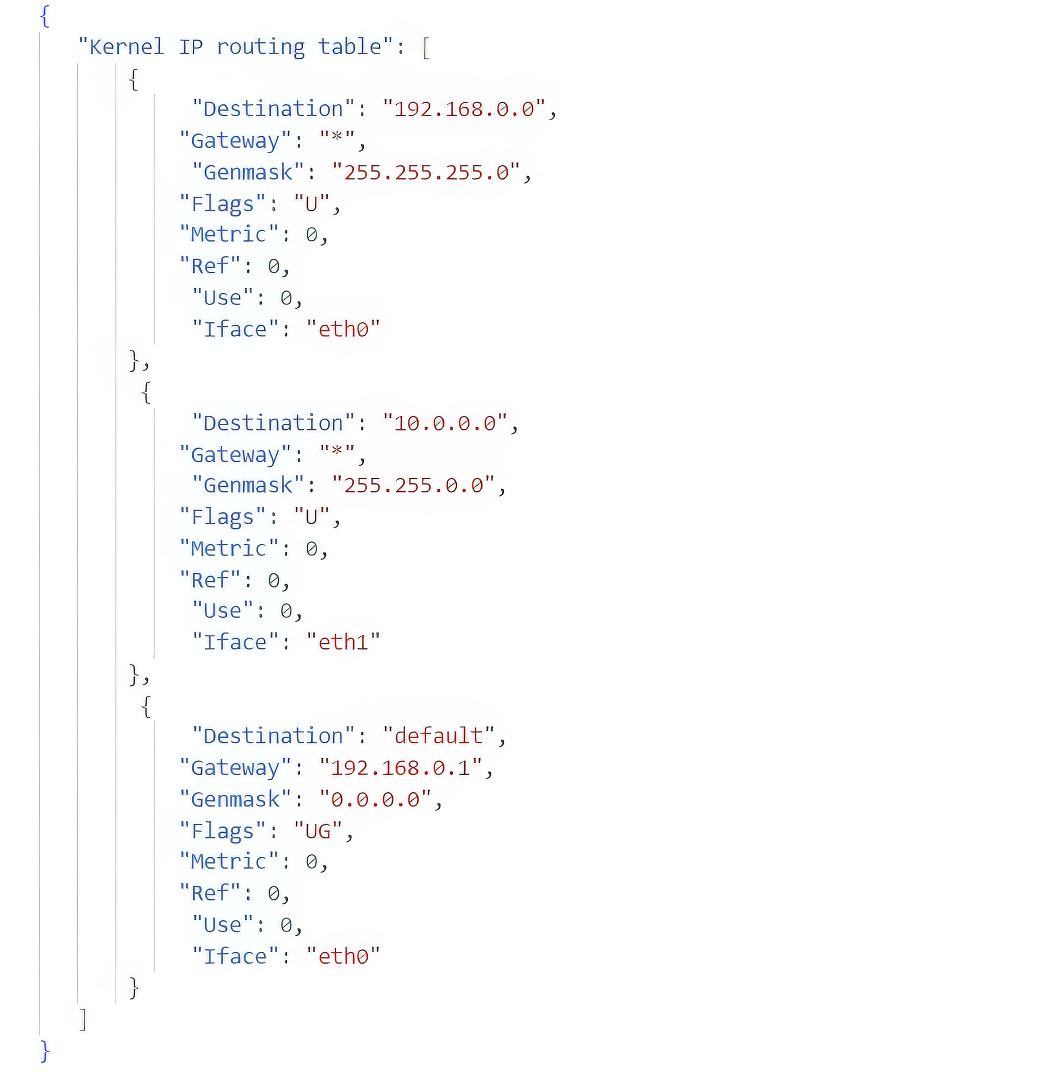
1st example

2nd example
Then, the automatic parser can be integrated in a web interface like the one shown below: on the left-hand side, the user loads the unstructured data. By clicking the loop button, the automatic parsers parse it and run the corresponding JSON data in the right-hand side of the application.





