Project overview
Building high-quality machine learning (ML) services requires not only extensive ML expertise, but also a large amount of high-quality training data from diverse sources. We re-think and address the needs for future machine learning where trust has increasingly not been established a priori among universal data owners and model owners.
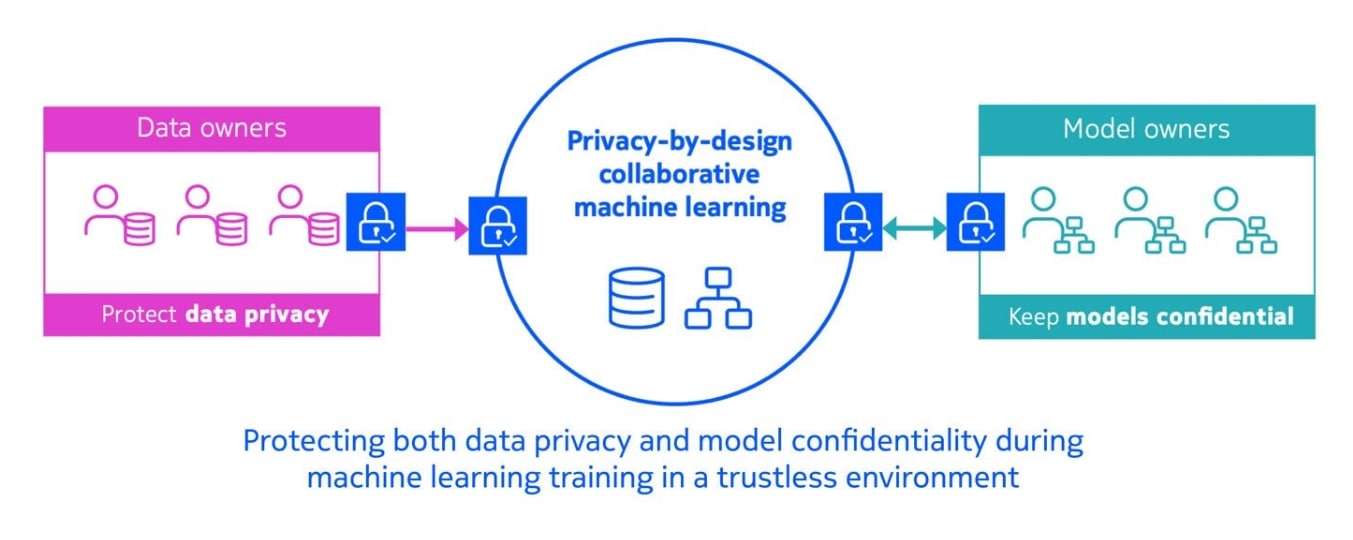
We develop solutions that remove this business friction between data and model owners, and enable the training of high-quality ML models while keeping both the training data private and the model confidential.
Today’s dilemma
Data owners’ challenges
Data owners have access to valuable information which demands data privacy, for example, banks maintain depositors’ financial records, hospitals keep patients’ healthcare data, and an ISP holds its infrastructure information. All such data is highly sensitive, and any data leaks can have a detrimental impact on individuals and businesses.
In addition, there are privacy regulations across the world, like the General Data Protection Regulation (GDPR) in Europe and the California Consumer Privacy Act (CCPA) in the US, that legally govern the sharing of private data and enforce the control and rights over such data.
Model owners’ challenges
Model owners design sophisticated models, however, often lack data from diverse sources to train generalizable models. Model owners demand model confidentiality, for example, a pharmaceutical company designs a model to help new drug designs, a FinTech company develops a fraud detection model to catch financial anomalies, or a solution provider designs a model to help ISPs identify infrastructure issues.
Models are becoming innovative, and model owners spend significant time and resources to develop and train their models. Thus, both the models and training methods are often intellectual properties and need to be kept confidential.
Collaboration between data owners and model owners is extremely beneficial. This facilitates an opportunity where data owners can share and monetize their valuable data, and model owners can train a better, generalizable model leveraging a larger dataset collectively contributed by multiple data owners. However today, they often do not trust each other. Data owners demand data privacy and model owners demand model confidentiality.
Our solution
The widely adopted industry solutions to collaborative machine learning today include Federated Learning and Split Learning. Here, a model is trained across multiple data owners holding local datasets, without exchanging them. However, such solutions have acknowledged limitations regarding the strong protection of both data privacy and model confidentiality.
We have created the Privacy-by-Design Collaborative Machine Learning service that protects both data privacy and model confidentiality throughout the entire ML training pipeline. Our service ensures each data owner’s dataset is treated in a provable privacy-preserving way. In addition, the confidentiality of model owners’ models and training methods is strongly protected where no entity other than the model owners ever has access to confidential models, even in a trustless environment.
With our service, there is no need for AI/ML developers or practitioners to change their daily routines. Instead, they program their model training code and then invoke our service APIs or use our GUI in the same way as they would program it for Federated Learning; thus, providing an easy-to-adopt, non-breaking experience for today’s developers and practitioners.
Our differentiators
A provable information barrier introduced into the ML model training pipeline through the secure aggregation and differential privacy mechanisms.
A principled sandboxing mechanism to regulate the information flow within the system.
Low to no entry barrier by following the same programming paradigm as in the traditional Federated Learning.
A scalable trusted execution environment to enforce confidentiality and compute integrity.
A convenient attestation service to gain user trust.
Learn more about our Entrepreneurs in Residence programs and projects.
Opportunity for collaboration
We are the pioneers for enabling collaborative AI/ML services in a trustless world. Our service enables an easy-to-adopt AI/ML eco-system where both data owners and model owners, though mutually untrusted, are willing to share and collaborate, with tangible gains and without losing market differentiation.
Interested in collaborating with us on this technology? Reach out to us!





APA style publications
- Zhifeng Jiang, Wei Wang, Ruichuan Chen, “Dordis: Efficient Federated Learning with Dropout-Resilient Differential Privacy,” to appear in Proc. ACM EuroSys 2024.
- Chengliang Zhang, Junzhe Xia, Baichen Yang, Huancheng Puyang, Wei Wang, Ruichuan Chen, Istemi Ekin Akkus, Paarijaat Aditya, Feng Yan, “Citadel: Protecting Data Privacy and Model Confidentiality for Collaborative Learning,” in Proc. ACM Symposium on Cloud Computing (SoCC) 2021.



